最佳实践
以下内容主要介绍通过容器实例、模型部署和分布式训练三种方式对LLaMA大语言模型进行调优、训练和部署。
一、容器实例
1.资源准备
创建容器实例,其中关键参数配置如下: 实例规格选择:1GB显存的A800(A800-80G*1 镜像选择:官方镜像pytorch:2.1.1-cuda12.1-cudnn8-ssh(镜像地址: registry.nervhub.nervstack.io/pytorch/pytorch:2.1.1-cuda12.1-cudnn8-runtime)
挂载代码和数据集
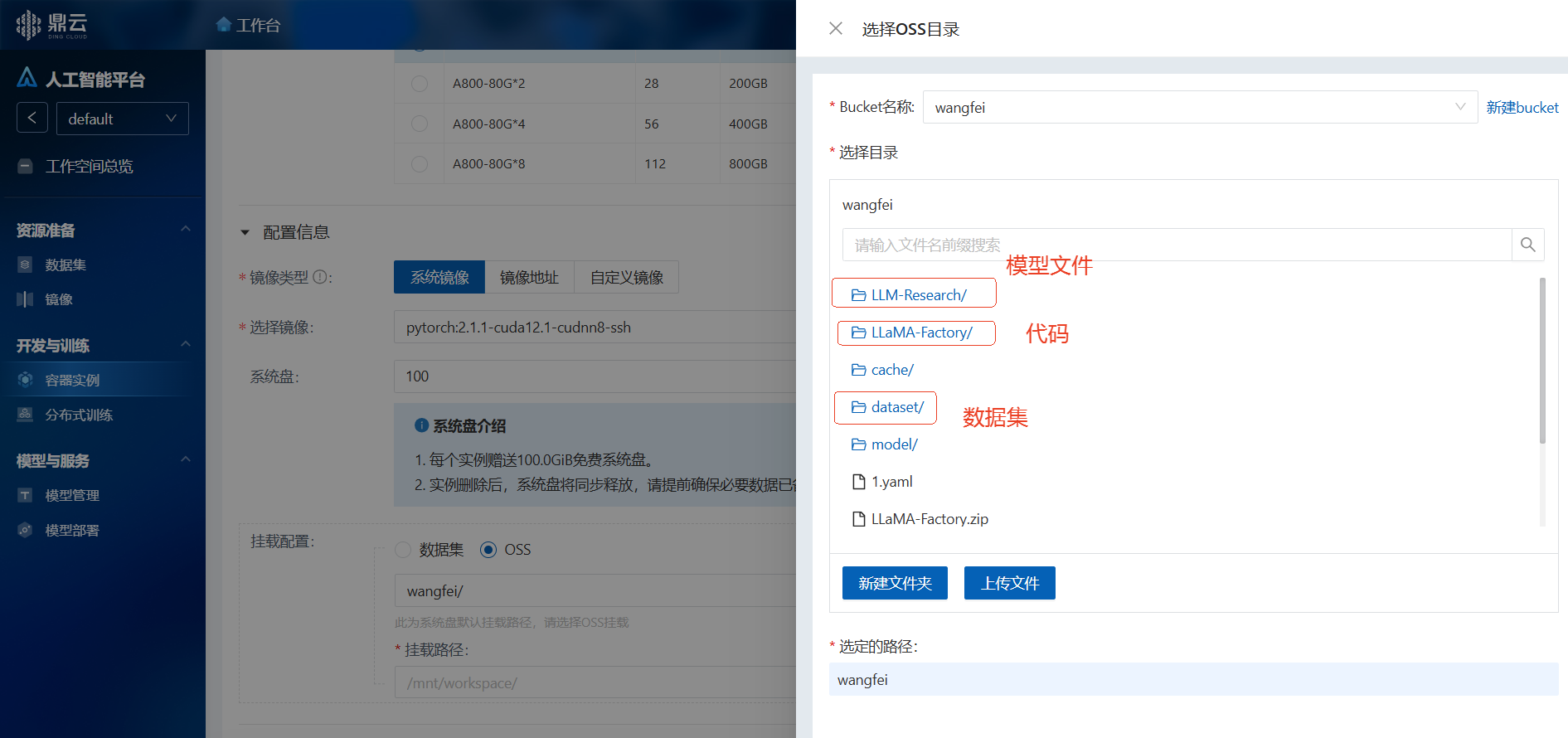
预览
2.准备环境
实例创建后,待实例变为运行中,点击“进入实例”:

预览
1.进入实例,开始准备所需环境:
shell
pip uninstall -y vllm
pip install llamafactory[metrics]==0.7.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install modelscope==1.14.0 -i https://pypi.tuna.tsinghua.edu.cn/simple2.检查是否安装成功
运行如下命令,如果显示llamafactory-cli的版本,则表示安装成功 llamafactory-cli version

预览
3.将下载的代码和数据集上传到对象存储或直接进入实例后下载
3.模型微调
3.1 启动webui
shell
cd /mnt/workspace/LLaMA-Factory
mv data rawdata && unzip ../dataset/data.zip -d data
export USE_MODELSCOPE_HUB=1 && \
llamafactory-cli webui单击返回的URL地址http://0.0.0.0:7860 ,进入Web UI界面。
3.2 配置模型参数
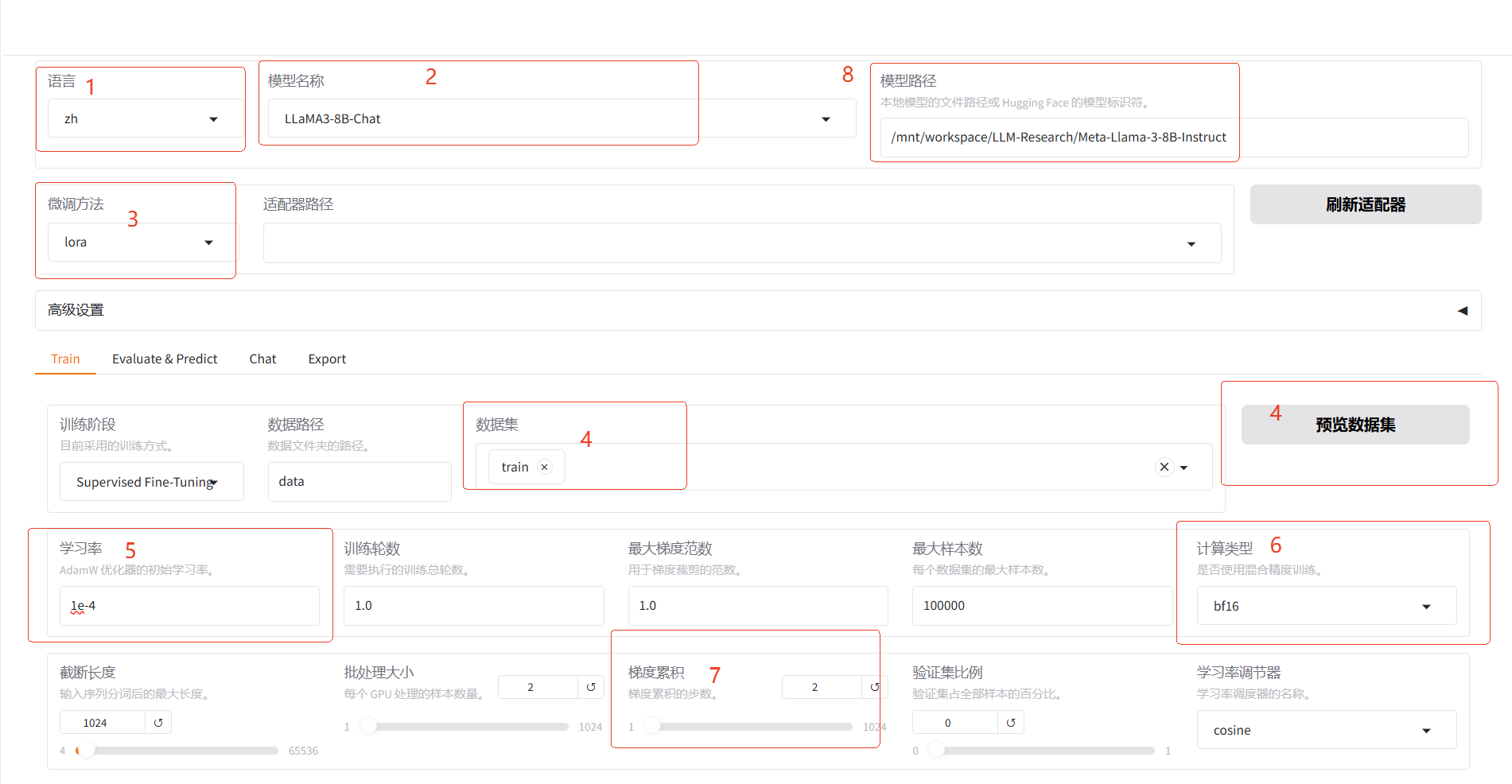
预览
预览
| 区域 | 参数 | 建议取值 | 说明 |
|---|---|---|---|
① | 语言 | zh | 无 |
| ② | 模型名称 | LLaMA3-8B-Chat | 无 |
| ③ | 微调方法 | lora | 使用LoRA轻量化微调方法能在很大程度上节约显存。 |
| ④ | 数据集 | train | 选择数据集后,可以单击预览数据集查看数据集详情。 |
| ⑤ | 学习率 | 1e-4 | 有利于模型拟合。 |
| ⑥ | 计算类型 | bf16 | 如果显卡为V100,建议计算类型选择fp16;如果为A10,建议选择bf16。 |
| ⑦ | 梯度累计 | 2 | 有利于模型拟合。 |
| ⑧ | 模型路径 | 本地模型路径 | 若上传了模型文件,建议指定本地路径 |
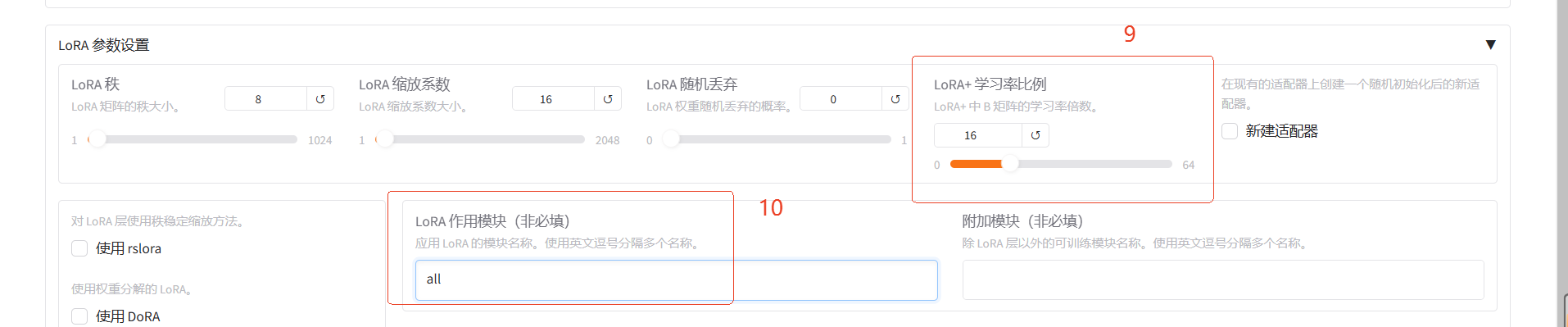
| ⑨ | LoRA+学习率比例 | 16 | 相比LoRA,LoRA+续写效果更好。 |
| ⑩ | LoRA作用模块 | all | all表示将LoRA层挂载到模型的所有线性层上,提高拟合效果。 |
3.3 启动微调
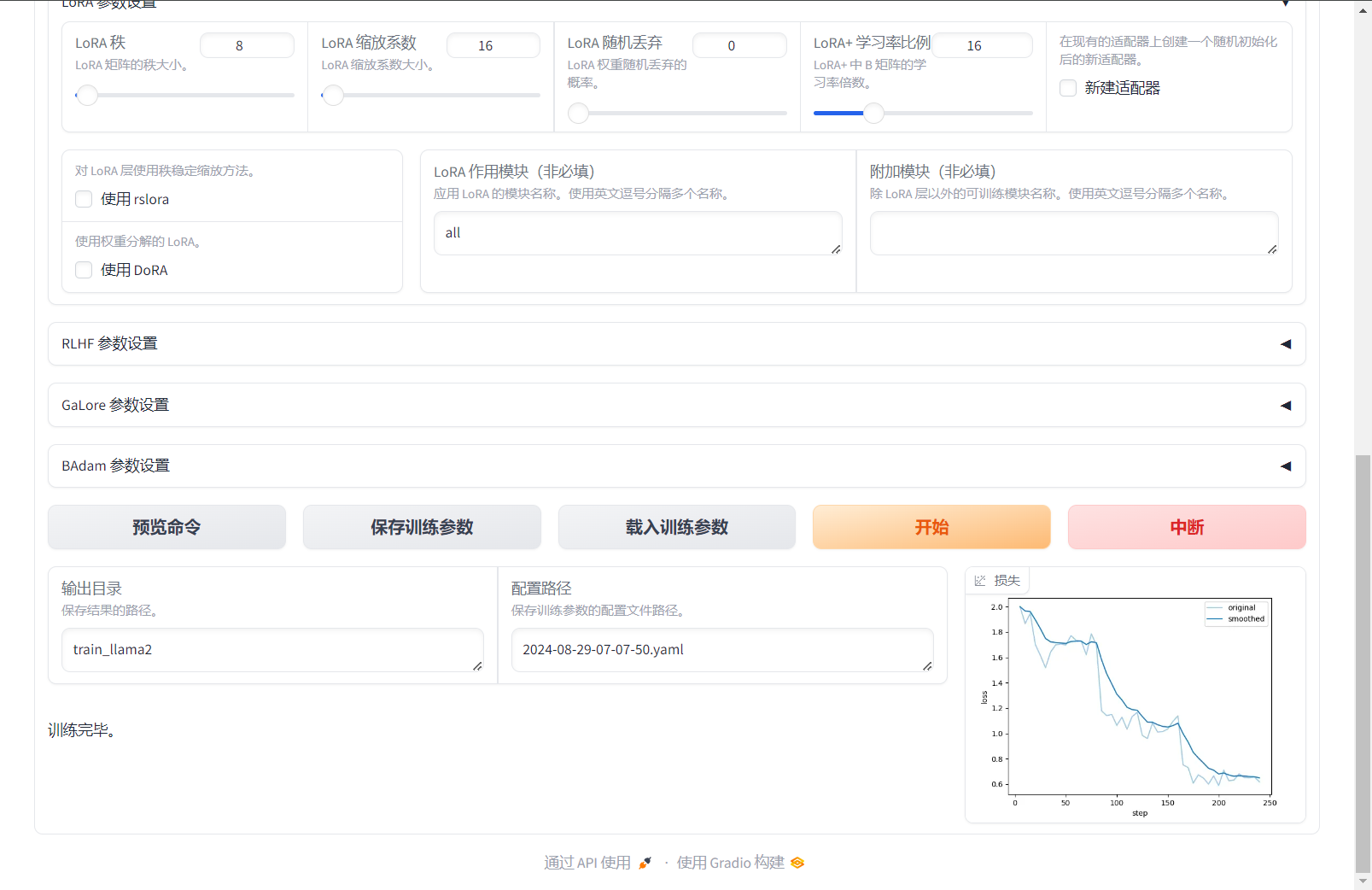
1.将输出目录修改为train_llama3,训练后的LoRA权重将会保存在此目录中。 2.单击预览命令,可展示所有已配置的参数。如果您希望通过代码进行微调,可以复制这段命令,在命令行运行。
3.单击开始,启动模型微调。 启动微调后需要等待大约20分钟,待模型下载完毕后,可在界面观察到训练进度和损失曲线。当显示训练完毕时,代表模型微调成功。
预览
3.4 模型评估
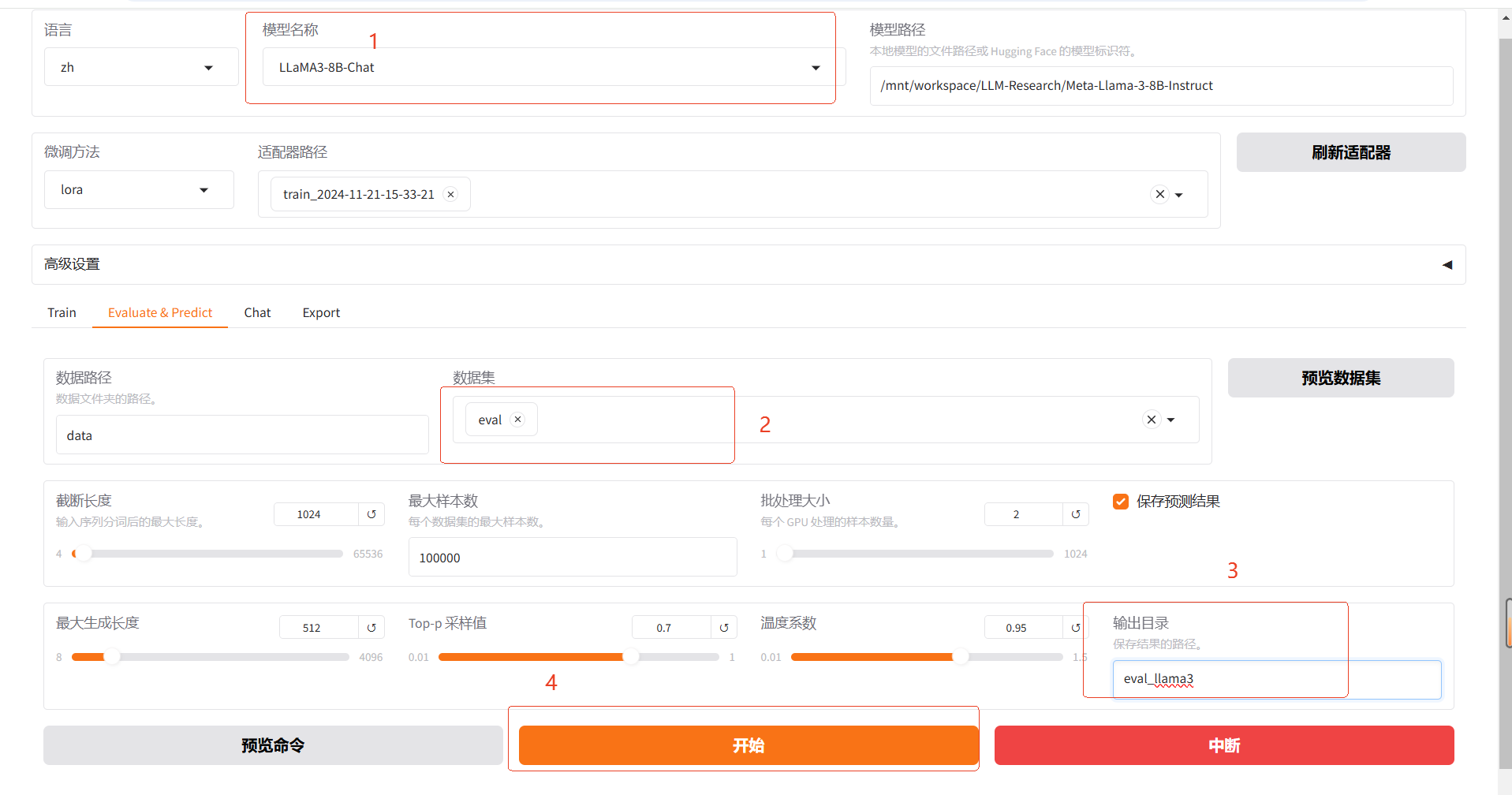
预览
1.模型微调完成后,单击页面顶部的刷新适配器,然后单击适配器路径,选择下拉列表中的train_llama3,在模型启动时即可加载微调结果。
2.在Evaluate&Predict页签中,数据集选择eval(验证集)评估模型,并将输出目录修改为eval_llama3,模型评估结果将会保存在该目录中。
3.单击开始,启动模型评估。
模型评估大约需要5分钟,评估完成后会在界面上显示验证集的分数。其中,ROUGE分数衡量了模型输出答案(predict)和验证集中的标准答案(label)的相似度,ROUGE分数越高代表模型学习得越好。
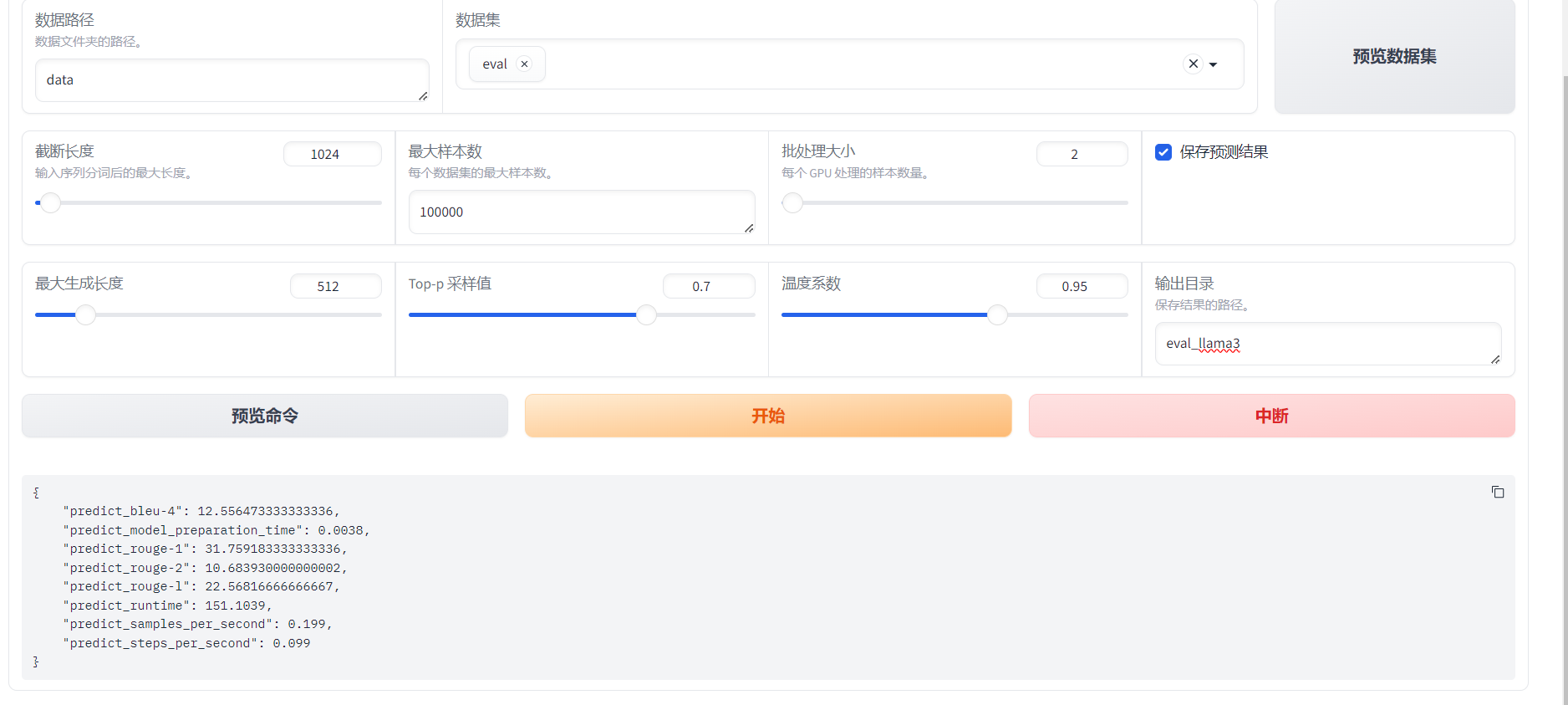
预览
3.5 导出模型
设置检查点路径,选择导出目录,导出完成将模型拷贝到oss,用于模型部署
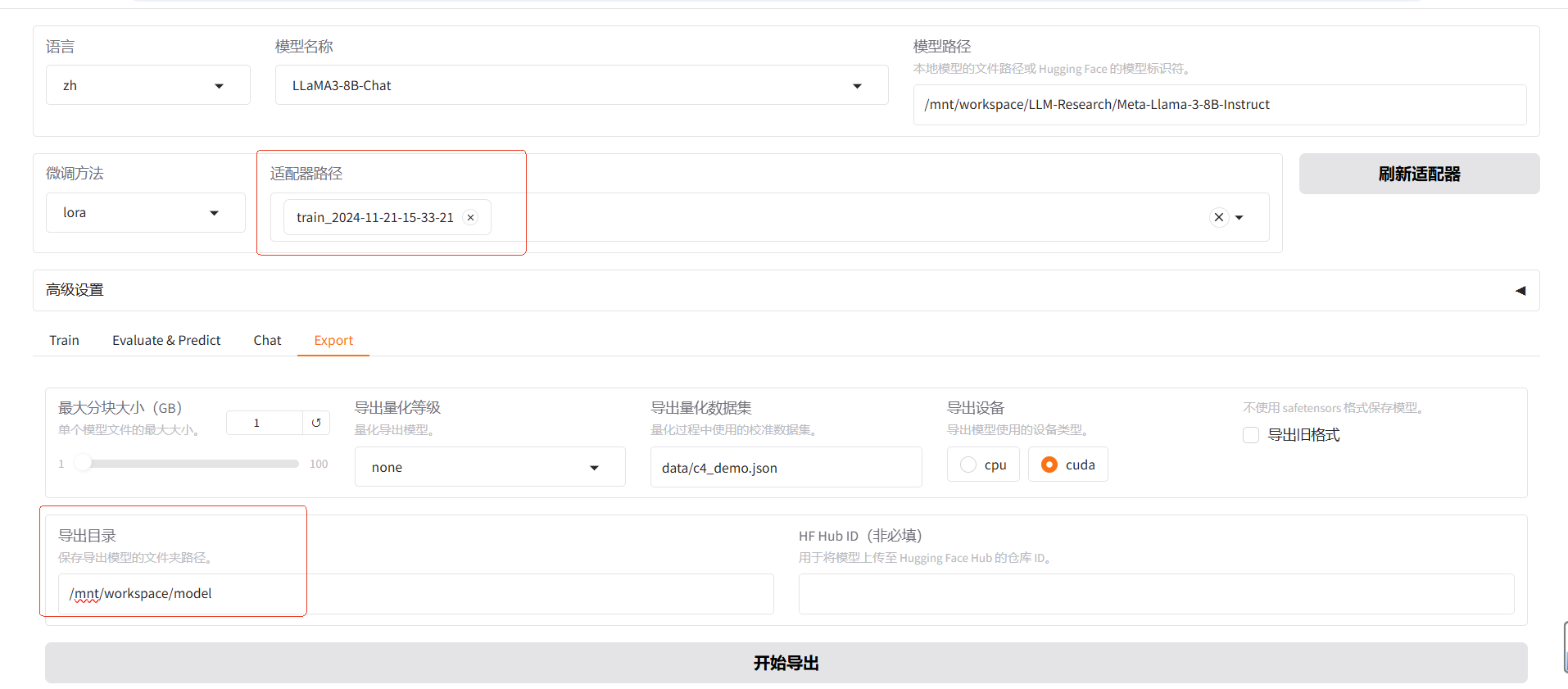
预览
3.6 保存镜像
1.操作栏点击制作镜像,方便后续部署模型
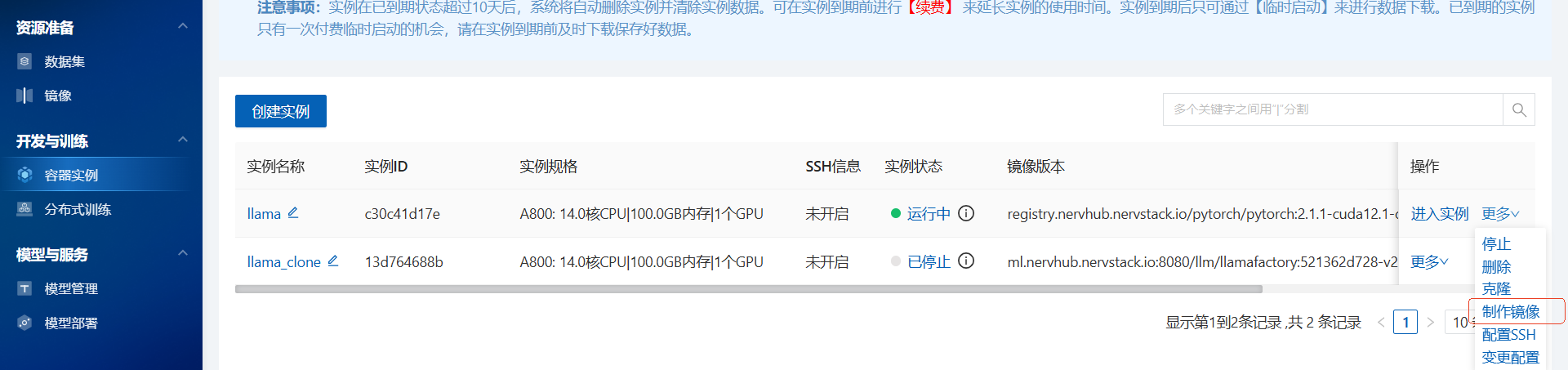
预览
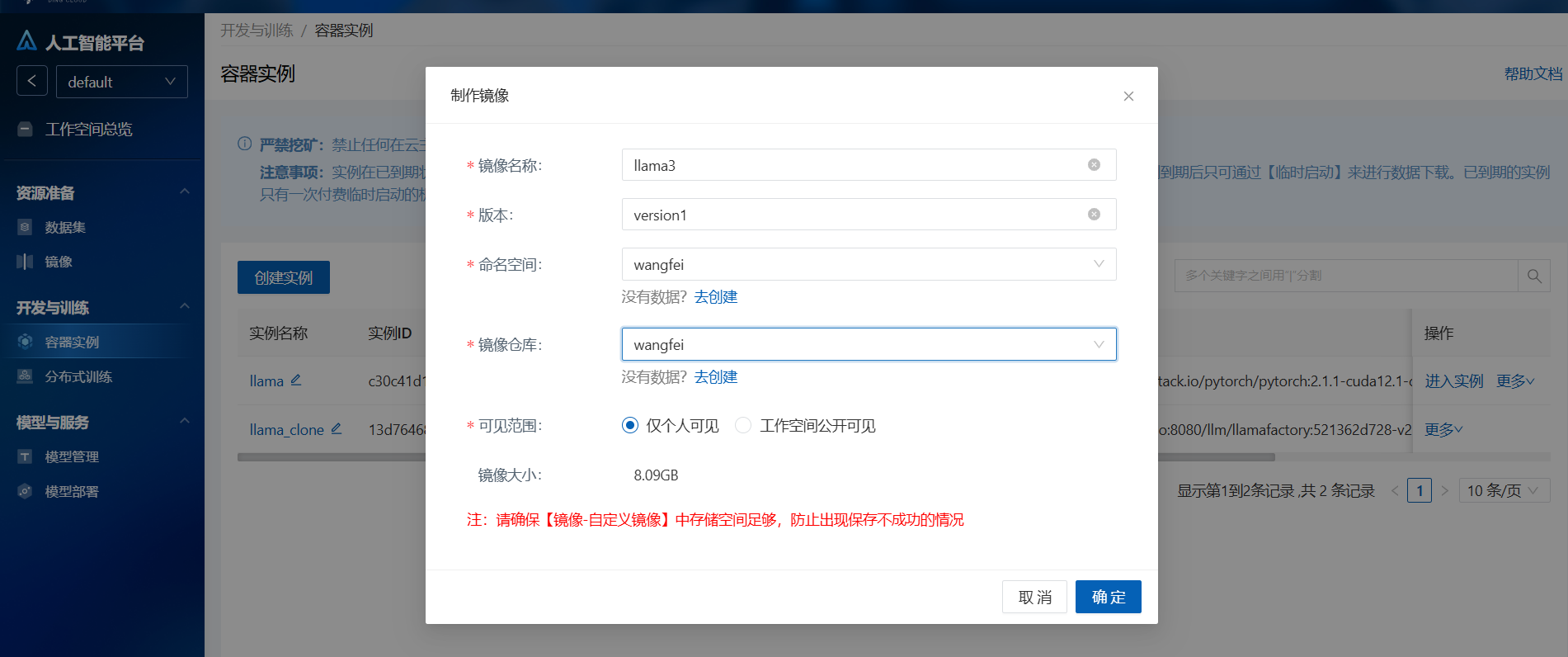
预览
2.镜像保存成功后进入自定义镜像,修改镜像使用模块并保存

预览
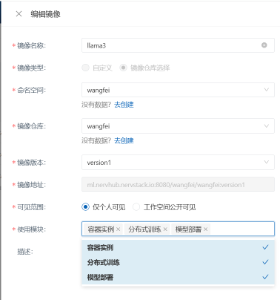
预览
二、模型部署
2.1开始部署
部署模型服务,其中关键参数配置如下:
部署方式:镜像部署AI-WEB应用
web端口号、端口号:7860
实例规格选择:1GB显存的A800(A800-80G*1)
镜像选择:自定义镜像,使用容器实例保存的镜像(llama3)
代码上传:
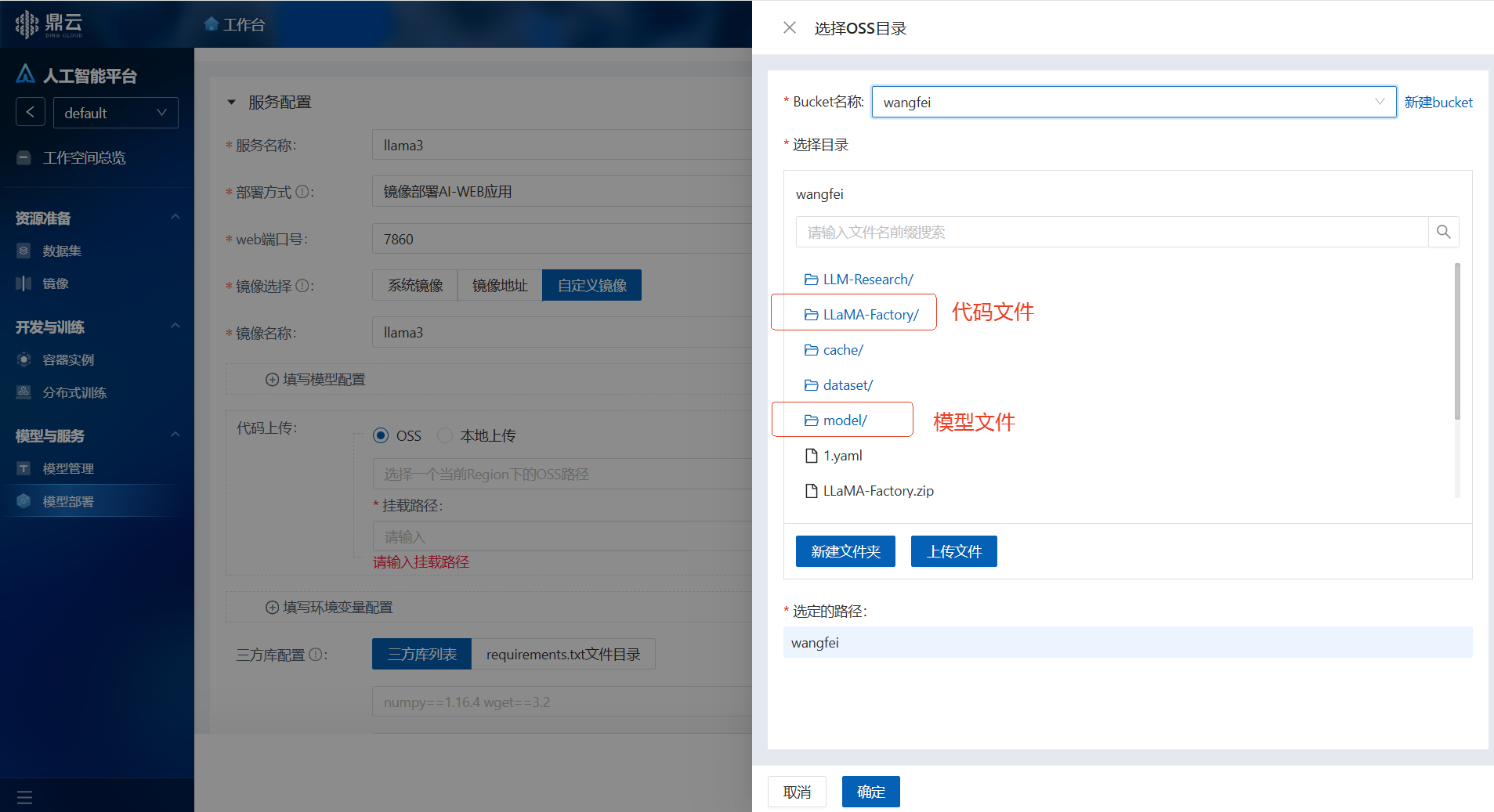
预览
执行命令:
shell
cd /code/LLaMA-Factory
export USE_MODELSCOPE_HUB=1 && \
llamafactory-cli webui2.2打开webUI
待模型服务进入运行中状态,点击“调用信息”
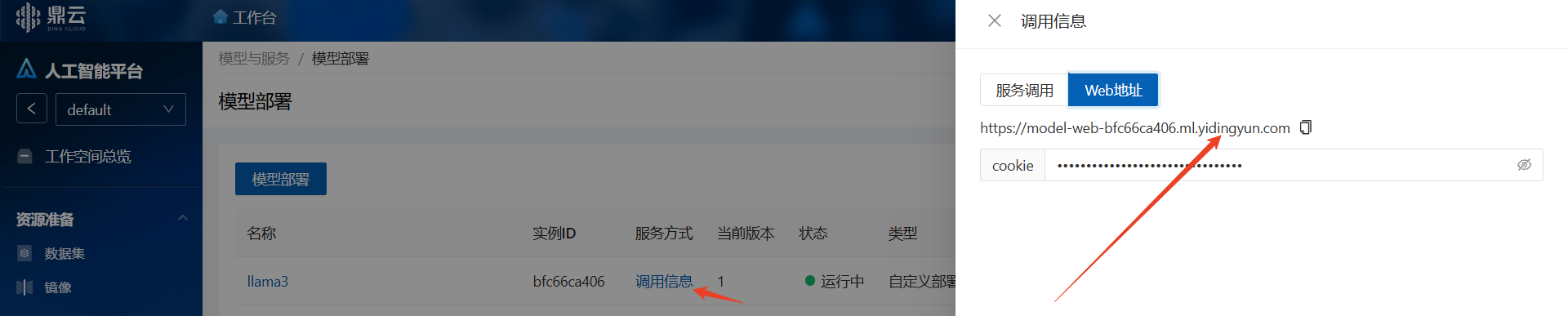
预览
复制web地址到浏览器打开: https://model-web-xxx.com
选择模型名称,输入模型路径加载模型,开始聊天
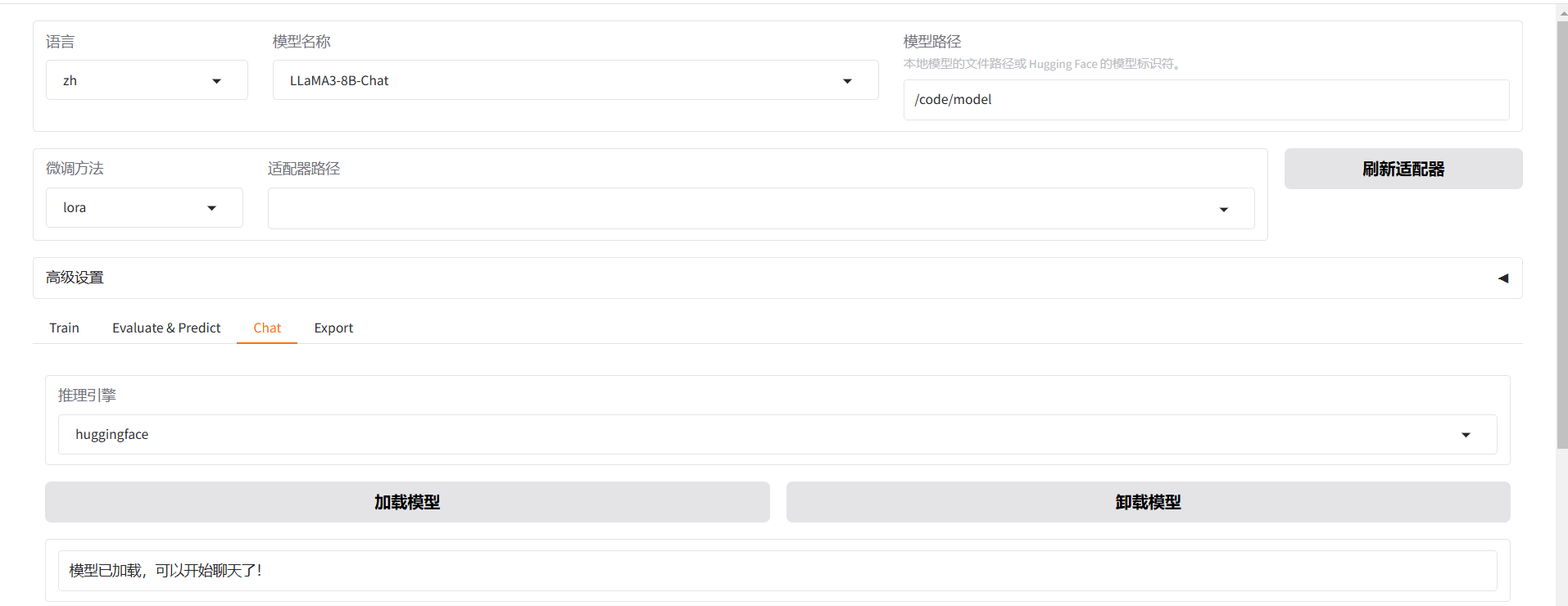
预览
三、分布式训练
3.1 开始新建
实例规格选择:1GB显存的A800(A800-80G*1) 镜像选择:自定义镜像,使用容器实例保存的镜像(llama3) 代码上传:挂载模型和代码等文件
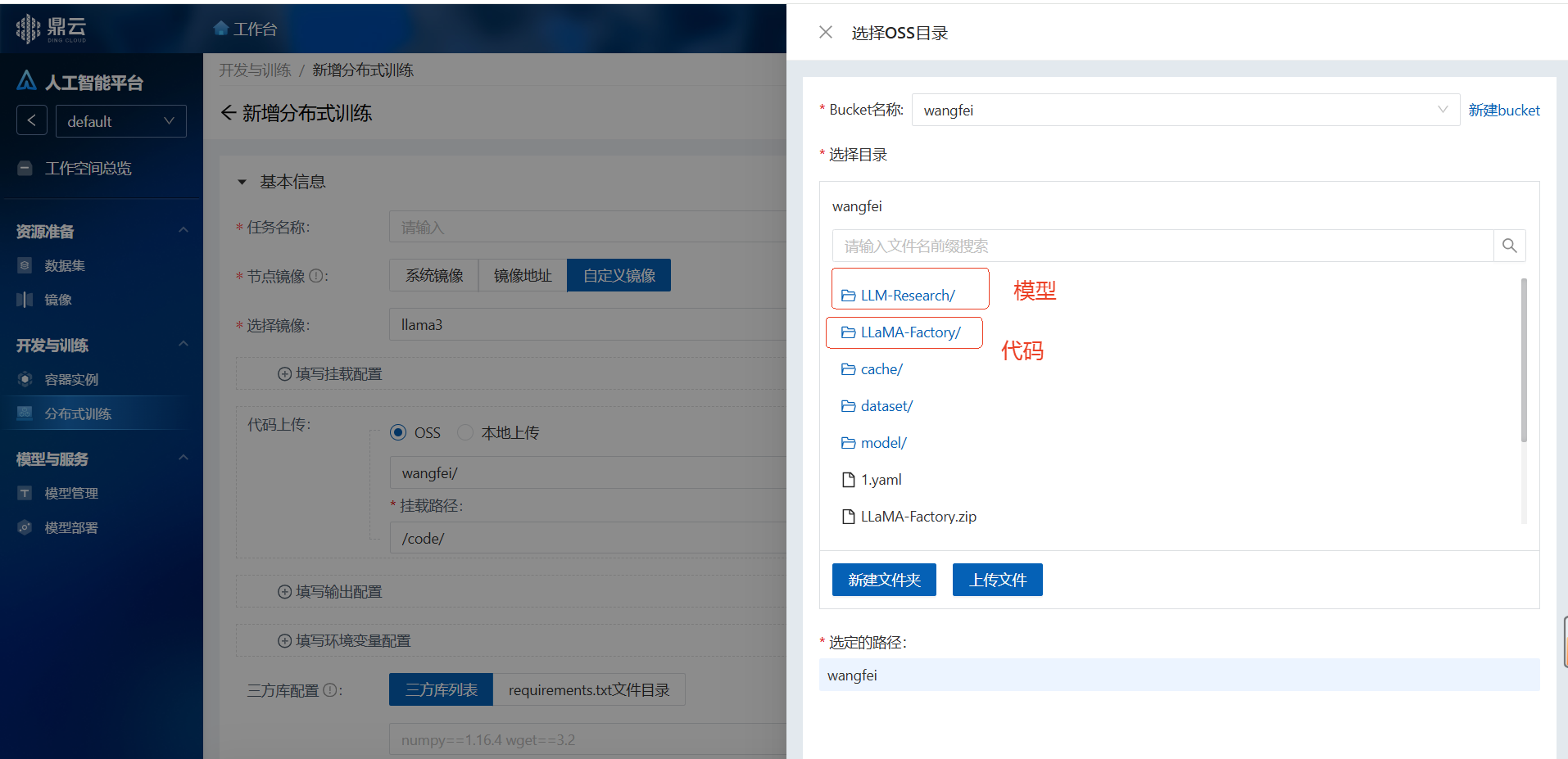
预览
执行命令:
shell
cd /code/LLaMA-Factory
export USE_MODELSCOPE_HUB=1 && llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path /code/LLM-Research/Meta-Llama-3-8B-Instruct/ \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--quantization_method bitsandbytes \
--template llama3 \
--flash_attn auto \
--dataset_dir data \
--dataset train \
--cutoff_len 1024 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--optim adamw_torch \
--packing False \
--report_to none \
--output_dir saves/output/train2 \
--bf16 True \
--plot_loss True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all3.2 查看输出
执行完成后,在对象存储查看输出结果
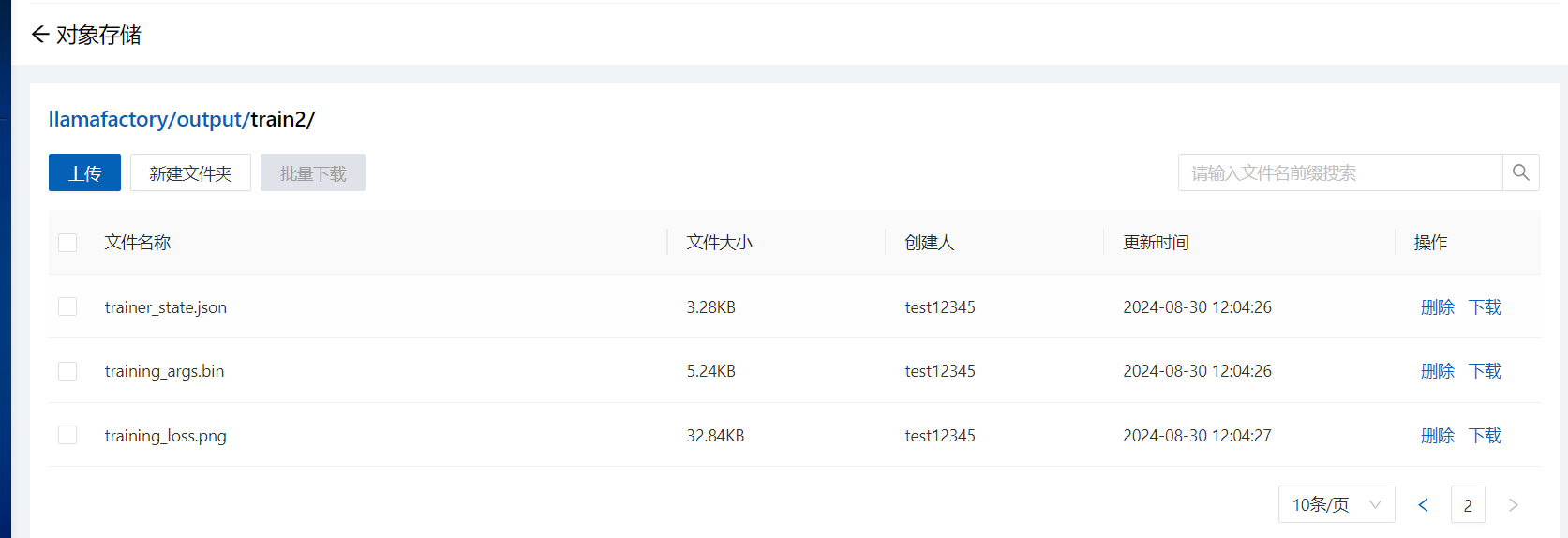
预览